Post Views: 1,573
In a previous blog post where I covered
Cross-Site Request Forgery and what potential impacts and consequences such an attack may have, I wrote that a popular way to prevent such an attack from unfolding is to generate tokens. In that blog post, I noted that when a website generates tokens, a CSRF attack might be stopped. One thing I did not cover though is that whether the attack will be stopped or not depends on how the tokens are implemented. Confused? Let me explain..
The anatomy of a Cross-Site Request Forgery attack
In order to make such an attack work, the attacker must know that you’re logged in to a web application and force your browser to make a request from an external source. The idea of Cross-Site Request Forgery tokens is that when an attacker is not able to guess what the token is (it should be a long, randomly generated string that is different on each request), he cannot mount an attack.
Let me show you an example. Here’s some source code courtesy of a login form with Cross-Site Request Forgery protection implemented correctly:

The above source code calls a generate function of a class called Token. The function generates a CSRF token as an MD5 hash that is unique on each request by utilizing a PHP function known as openssl_random_pseudo_bytes, meaning that the token is random and cannot be predicted. That’s one way. However, CSRF tokens can also be seen being implemented like this:
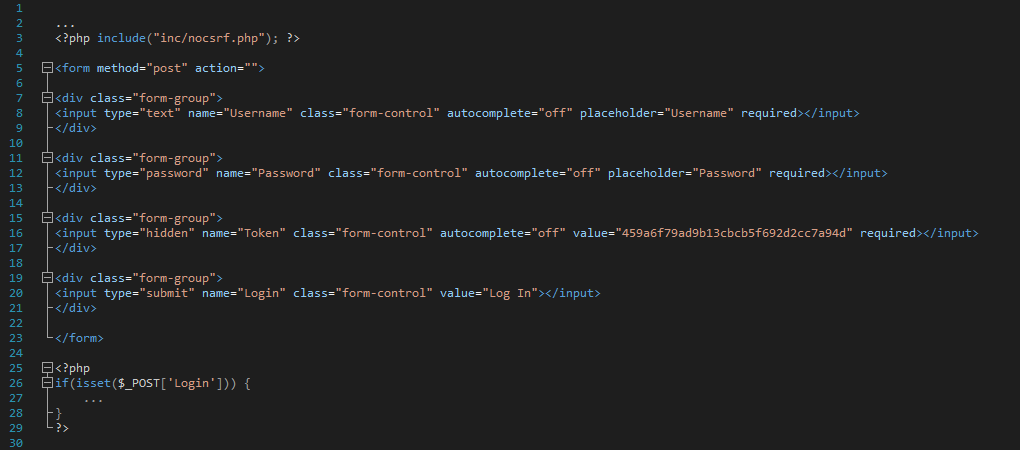
Now this is bad. Take a look at line #16: not only the CSRF token is not generated, it’s hardcoded. This does not bother an attacker very much: a nefarious party can still place a payload on a malicious website that, upon execution, could change the user’s password without his knowledge, or, in this case, log the user in to a web application: if the token is not random, it becomes completely useless.
Why are hardcoded CSRF tokens useless?
Imagine a potential attacker testing your web application for CSRF: your website might contain a page which allows users to send money to a different account. In order to know if it is vulnerable to such a flaw, an attacker could view the source code of the page. As he would see a token that is being generated, he would automatically assume that your website is protected against Cross-Site Request Forgery (tokens are not the only way to protect against such an attack, but it is the most widely used approach). He refreshes the page and views the source code. The token is the same. He refreshes the page once again. The token is the same. He reloads the page once more: the CSRF token is still the same meaning the request can still be successfully forged.
Are your tokens valid?
Seeing CSRF tokens being implemented is great, but web developers must not forget that in order for the CSRF protection to actually work, the token must be validated on the server-side, otherwise such an approach is ineffective. For example, an open-source forum called VanillaForums was once susceptible to CSRF even though tokens were being generated – the creators of the software created a key called “TransientKey” which was supposed to act as an CSRF token, but here’s the issue: the token was random, but the server-side did not do any validation on the token, which might have allowed an attacker to forge a request.
Summary
Tokens are a powerful defense against Cross-Site Request Forgery, but that’s only the case if the tokens are implemented properly. In order to make sure your token-generating web application is protected against CSRF, ask yourself these questions:
- Are the tokens random?
- Are the tokens unique for each request?
- Are they being validated?
If you’ve answered “Yes” to all three questions and you’re combatting this flaw by generating tokens (there are other ways as I noted before), congratulations. Your web application is most likely guarded against Cross-Site Request Forgery.